

Conceptos básicos
¿Para qué le va a servir este módulo?
El módulo 1 de este curso está diseñado para que los servidores y servidoras públicos se familiaricen con los conceptos básicos del tema de datos y estadística en la gestión pública, y mejoren y amplíen su conocimiento sobre:
✔La necesidad de contar con información e indicadores para la toma de decisiones.
✔La necesidad de tener y usar datos desagregados que reflejen la situación real del municipio y los grupos poblacionales para poder cumplir con el propósito de atender de manera diferenciada las necesidades de la ciudadanía.
¿Por qué son importantes los datos?
Empecemos con un ejercicio que nos ayuda a hacernos conscientes del papel que cumplen los datos en la toma de decisiones.
Imagínate que juegas en la Selección Colombia y en tu primer partido tienes la responsabilidad de cobrar un tiro penal en el último minuto. Si conviertes el gol, la selección clasificará al próximo mundial. Si no, se queda por fuera…

¿Hacia dónde patearías el balón?
¡Elige una opción antes de seguir! Puedes anotarla en una libreta o guardarla en tu memoria.
a. Esquina superior derecha.
b.Esquina inferior derecha.
c. Centro arriba.
d. Centro abajo.
e. Esquina superior izquierda.
f. Esquina inferior izquierda.
¿Ya elegiste una respuesta?
Pues bien, en esta unidad aprenderás que las estadísticas pueden ayudarte a tomar una decisión como esta.
Con esto, irás aprendiendo que, al trabajar en el contexto del servicio público, donde las decisiones que se toman son mucho más importantes que la clasificación de un equipo a un torneo, es fundamental aumentar nuestro conocimiento y nuestras capacidades para trabajar con datos y estadísticas.
LA UTILIDAD DE LOS DATOS EN LA TOMA DE DECISIONES
Una empresa especializada en estadística llamada InStat revisó los datos sobre más de 100 mil tiros penales en diferentes torneos mundiales entre 2009 y 2018, y encontró que:
- 3 de cada 4 lanzamientos terminan en gol (75,5%)
- 17,6% de los cobros son parados por el portero
- 4% salen desviados
- 2,8% chocan contra el palo
Además, los datos revisados revelaron cuáles son las zonas que tienen mayor probabilidad de gol.

Otro estudio de “The Stat Zone” recopiló y analizó datos de 26 tandas de penales en Copas Mundiales (hasta 2018), y 18 tandas de la Eurocopa (hasta 2016). Este estudio reveló cuáles son las zonas con mayor probabilidad de éxito en el cobro, no sólo en total sino también de acuerdo al pie con el que pateó el cobrador.
¿Qué opinas tú? ¿Tiene más probabilidad de éxito un pateador zurdo o uno derecho?
¡Mira los datos!
Cada uno de los recuadros que verás a continuación representa un arco dividido en 12 zonas. Los recuadros muestran el porcentaje de penales convertidos en cada una de las zonas.
A la izquierda se muestran los datos del total de penales considerados en el estudio. En el medio se muestran los datos de los penales pateados con la pierna derecha. Y en la derecha se muestran los datos de los penales pateados con la pierna izquierda.

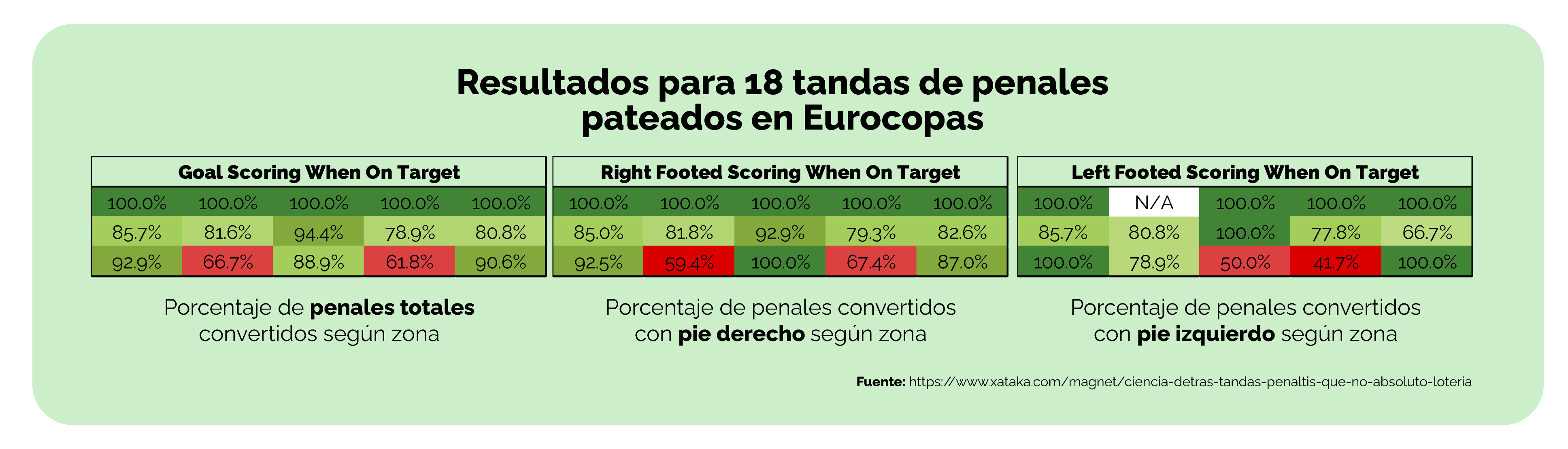
Fuente: https://www.xataka.com/magnet/ciencia-detras-tandas-penaltis-que-no-absoluto-loteria
Después de haber mirado estas imágenes que muestran las zonas del arco en las que más se convirtieron penales y las zonas del arco en las que menos se convirtieron, ¿qué pasaría si te volvieran a preguntar hacia dónde patearías el tiro penal del que depende que la selección Colombia clasifique al próximo mundial? ¿Cambiarías tu decisión?
Respóndete a ti mismo esta pregunta antes de seguir… ¿Sí cambiarías la decisión? ¿No cambiarías la decisión?
Si respondiste que SÍ, es porque al ver y analizar los datos presentados por estos estudios te diste cuenta de que tu decisión inicial no tenía una probabilidad alta de ser exitosa. Por eso, decidiste cambiar de opinión y cobrar el penal hacia un lugar con mayor probabilidad de gol.
Si respondiste que NO, pudo ser porque tu respuesta inicial era patear hacia una zona con alta probabilidad de éxito y por eso decidiste continuar con esta estrategia para cobrar el penal.
En ambos casos, tanto si respondiste SÍ como si respondiste NO, los datos te permitieron: revisar tu estrategia, aprender de las experiencias documentadas en los estudios presentados, y tomar una mejor decisión.
En esta unidad, a partir del ejercicio del tiro penal imaginario, has afianzado un conocimiento fundamental para los servidores y las servidoras públicos. Ese conocimiento puede ser resumido así:
✔ Recopilar y sistematizar los datos permite analizarlos
✔ Visualizar los datos ayuda mucho a entenderlos mejor
✔ Los datos permiten aprender de experiencias propias o de otros
✔ Los datos ayudan a evaluar y definir mejores estrategias
✔ Los datos permiten tomar decisiones basadas en evidencia
Con el fin de que los datos sean útiles para definir mejores estrategias y tomar mejores decisiones en el contexto del servicio público, deben ser recopilados, analizados y usados en las diferentes fases del ciclo de la gestión pública.
En esta unidad aprenderás cómo se pueden y deben utilizar los datos en cada una de las fases de este ciclo.

USO DE DATOS EN LA PLANEACIÓN
En esta fase se utilizan los datos porque es necesario caracterizar a la población del municipio o a la población objetivo de un programa o proyecto. También se usan los datos para diagnosticar situaciones (problemas o necesidades) que se deben abordar, definir estrategias y establecer metas.
USO DE DATOS EN LA EJECUCIÓN
En esta fase se utilizan los datos porque es necesario recopilar la información sobre los logros y las dificultades en la implementación de proyectos, programas o políticas públicas.
En esta fase es fundamental la recopilación de información física y financiera, porque permite establecer cómo la inversión de los recursos se ve reflejada en la provisión de bienes y servicios (productos), para después analizar su impacto en el bienestar de la población (resultados).
USO DE DATOS EN EL MONITOREO Y SEGUIMIENTO
En esta fase se utilizan los datos porque es necesario analizar la información que fue recogida en la fase de ejecución para evaluar el cumplimiento de metas y revisar los resultados.
USO DE DATOS EN EL APRENDIZAJE
En esta fase, se utilizan los datos porque es necesario analizar los datos de la fase de seguimiento, revisar los resultados de la implementación, y decidir si hay que cambiar o ajustar estrategias o si lo mejor es continuar sin cambios.
Más adelante, en el módulo 2 de este curso, profundizarás en este tema y mejorarás tus capacidades para utilizar los datos en cada una de las fases de la gestión pública. Antes de esto, es necesario que en el módulo 1 aprendas algunos de los conceptos básicos de los datos y la estadística y su relevancia para la gestión pública.
¡VERIFICA LO APRENDIDO!
Estos son algunos de los datos que utilizamos frecuentemente como servidores públicos:
- Porcentaje de población femenina
- Población en edad escolar
- Tasa de desempleo
- Tasa de pobreza multidimensional
- Tasa de cobertura neta en educación
En esta unidad aprenderás cuáles son las principales fuentes de las que provienen estos datos.
OPERACIONES ESTADÍSTICAS
El Departamento Administrativo Nacional de Estadísticas -DANE- define de esta manera una operación estadística:
Es el conjunto de procesos y actividades que comprende la identificación de necesidades, diseño, construcción, recolección o acopio, procesamiento, análisis, difusión y evaluación, el cual conduce a la producción de información estadística sobre un tema de interés nacional y/o territorial.
Es una definición un poco complicada, ¿cierto? Pero, si lees la definición con detenimiento, verás que una operación estadística comprende todas las actividades requeridas para producir datos estadísticos sobre temas que son relevantes para la nación o para uno o varios territorios específicos.
Hay operaciones estadísticas cuya fuente es información primaria, y hay otras operaciones estadísticas que utilizan información secundaria (como registros administrativos, datos geográficos o big data) como insumo para producir información estadística. En esta unidad aprenderás qué las diferencia y conocerás algunos ejemplos de operaciones estadísticas de fuente primaria con las que los servidores públicos suelen trabajar, así como de conjuntos de datos que son utilizados como fuentes secundarias para efectuar operaciones estadísticas.
OPERACIONES ESTADÍSTICAS DE FUENTE PRIMARIA
Una operación estadística de fuente primaria es una operación estadística que obtiene los datos directamente de las unidades estadísticas (personas, hogares, empresas, etc).
Las operaciones estadísticas de fuente primaria son útiles e importantes porque, además de obtener información directamente del grupo objetivo (personas, empresas), en ellas se tiene control de todo el proceso estadístico. Esto quiere decir que en las operaciones estadísticas de fuentes primaria:
✔ Los datos recopilados obedecen a las necesidades de información requeridas
✔ Se usan conceptos estandarizados
✔ Hay control sobre la muestra y la representatividad de los datos
✔ Hay control sobre los métodos de recolección y análisis de los datos.
A continuación, verás dos ejemplos de operaciones estadísticas de fuente primaria de las cuales provienen muchos de los datos que son útiles para la gestión pública.
EL CENSO
El censo es una operación estadística que consiste en el conteo de todos y cada uno de los elementos de una población o de un universo, en un lugar determinado y en un tiempo dado.
Estos son algunos ejemplos de censos:
• El Censo Nacional de Población y Vivienda de 2018
Consiste en contar y caracterizar las personas residentes en Colombia (sexo, pertenencia étnica, nivel cultural, situación económica), así como las viviendas y los hogares del territorio nacional.
• El Censo Arbóreo Total de Ciudad
Consiste en el levantamiento de un conjunto de datos básicos asociados a las características y el entorno de la población de árboles
• El Censo Electoral 2023
Consiste en contar a todas las personas, mayores de 18 años, inscritas para ejercer el derecho al voto en el país.

CENSOS DE POBLACIÓN Y GESTIÓN PÚBLICA
Los datos estadísticos que se obtienen de los censos de población sirven para entender cómo se distribuye la población según sexo y grupos de edad. Esto es útil porque a partir de estos datos se pueden hacer cosas relevantes para la gestión pública. Algunas de esas cosas que se pueden hacer con ellos son:
✔ Ver cómo evoluciona la estructura poblacional en el tiempo.
✔ Analizar las necesidades de la población, de acuerdo con la distribución de personas en cada grupo poblacional y su evolución en el tiempo.
✔ Conocer la estructura de los hogares y la condición de las viviendas en las que habitan.
Veamos ahora un ejemplo:
Supongamos que los datos de un censo y su proyección (creada a través de información secundaria como datos de nacimientos, defunciones o migración) muestran una reducción de la población en edades entre los 0 y los 18 años.
Estos datos estadísticos pueden analizarse en relación a las necesidades de educación, pues se puede asumir que habrá menos demanda de educación al tener menos niños y adolescentes que atender.
Esta imagen muestra cómo evolucionará la estructura de la población, en los próximos 10 años, en un municipio:
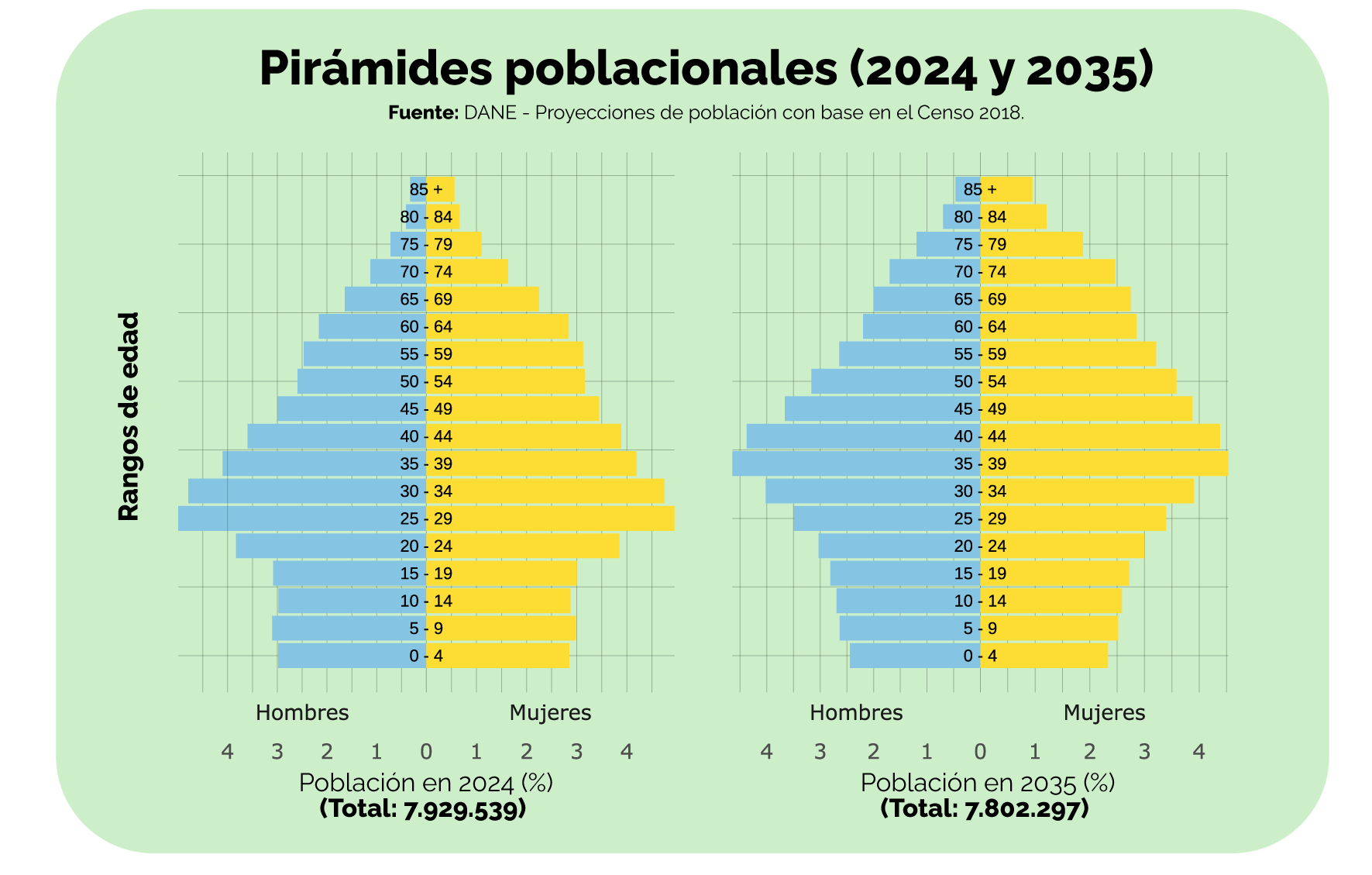
Como se ve en la gráfica, la población de 0-4 años pasa de representar el 5,8% en 2024 al 5% en 2035, y la población en edad escolar (5 a 24 años) pasaría, aproximadamente, del 26% en 2024 al 22.2%, mientras que la población de adultos mayores (60 años o más) pasaría de representar el 15,2% en 2024 al 20% en 2035.
Por lo tanto, en este municipio será necesario incrementar la atención que se brinda a los adultos mayores mientras que irá disminuyendo la cantidad de servicios que requiere la población más joven.
LAS ENCUESTAS
Las encuestas son una operación estadística que informa sobre un tema determinado, pero no sobre toda una población específica.
Existen dos tipos de encuestas: encuestas por muestreo aleatorio o probabilísticas, y encuestas no aleatorias o no probabilísticas. A continuación, aprenderás cuáles son sus diferencias y qué debemos tener en cuenta al utilizar la información estadística que producen.
ENCUESTAS POR MUESTREO ALEATORIO O PROBABILÍSTICAS
Son encuestas que seleccionan aleatoriamente una parte de la población, que se llama “muestra” y que se considera representativa de la población de interés, de tal manera que a partir de la información recogida se puedan hacer inferencias sobre toda la población.
Son ejemplos de encuestas por muestreo:
- La Gran Encuesta Integrada de Hogares (GEIH)
- Encuesta de Calidad de Vida
- Encuesta Nacional de Uso del Tiempo (ENUT)
- Encuesta de Percepción Ciudadana Bogotá cómo vamos
Esta imagen ilustra, con un ejemplo específico, el funcionamiento de las encuestas por muestreo. En este caso, se trata de la Gran Encuesta Integrada de Hogares -GEIH-

En el ejemplo, la población objetivo corresponde a la “Población en edad de trabajar -PET-”. Como resulta difícil y muy costoso encuestar a todas estas personas, el DANE realiza un muestreo probabilístico para seleccionar una parte de esta población (muestra) que represente las características de la PET (sexo, edad, nivel educativo, situación laboral, ingresos, etc.) para aplicarles una encuesta. A través de las respuestas que se obtienen de estas personas, se pueden calcular datos que reflejen la situación laboral de toda la PET del país. Por ejemplo, se pueden calcular las tasas de desempleo, de ocupación, de participación y demás indicadores del mercado laboral.
UNA ADVERTENCIA IMPORTANTE SOBRE LA INFORMACIÓN PRODUCIDA CON ENCUESTAS DE MUESTREO ALEATORIO
En el caso de los datos producidos a través de encuestas por muestreo es fundamental no cometer errores a la hora usar e interpretar sus resultados. Hay encuestas que tienen representatividad a nivel nacional, otras a nivel departamental, otras para las 13 principales ciudades, etc.
En este sentido, los resultados de una encuesta con representatividad departamental no pueden ser extrapolados a nivel municipal porque la muestra no está diseñada para reflejar las características de los municipios, sino solo la de los departamentos.
NOTA: Para poder extrapolar los resultados de una encuesta con representatividad departamental a nivel municipal, los estadísticos aplican metodologías de muestras pequeñas que, acompañadas por registros administrativos, pueden lograr ampliar la representatividad. Sin embargo, este proceso solo puede realizarse por estadísticos expertos en estos temas.
ENCUESTAS NO ALEATORIAS O NO PROBABILÍSTICAS
Son encuestas en las que la selección de los encuestados no se hace de forma probabilística. Por esta razón, los resultados informan únicamente sobre la población que fue encuestada.
Por ejemplo, si alguien decide aplicar una encuesta a los residentes de un edificio, estos resultados solo informan sobre las preferencias o la situación de las personas entrevistadas de ese edificio en particular, pero no se puede afirmar que estos resultados son aplicables a todo el barrio o la localidad en donde se ubican dichas personas.
OPERACIONES ESTADÍSTICAS Y FUENTES SECUNDARIAS
Los datos que utilizamos como servidores públicos no sólo vienen de operaciones estadísticas de fuente primaria. También pueden provenir de operaciones estadísticas que han utilizado fuentes secundarias.
Una de esas fuentes secundarias son los registros administrativos. Es importante recalcar que los registros administrativos no son en sí mismos operaciones estadísticas, pero pueden ser incorporados en ellas después de un proceso que evalúa su potencial para tal fin.
REGISTROS ADMINISTRATIVOS
Los registros administrativos son el conjunto de datos que contiene la información recogida y conservada por entidades y organizaciones en el cumplimiento de sus funciones o competencias misionales. Esto quiere decir, que abarcan la información recolectada, almacenada y administrada de manera continua por instituciones públicas y privadas sobre personas naturales, jurídicas, o cualquier otra unidad de observación.
Son ejemplos de registros administrativos:
- SISBEN
- SISPRO
- REGISTRO UNICO DE VÍCTIMAS
- Check-Mig

Aun cuando los registros administrativos no tienen propósitos estadísticos, los datos que recopila son valiosos para conocer el comportamiento de los fenómenos o situaciones que representan. Por ejemplo, los datos de matrícula de los colegios se pueden utilizar para calcular las tasas de cobertura en educación, o los registros de muertes por accidentes de tránsito se pueden utilizar para calcular la tasa de homicidios en accidentes de tránsito por cada 100 mil habitantes.
Para que la información producida por operaciones estadísticas que incorporan información de lo registros administrativos sea útil para la toma decisiones, esta información debe ser:
✔ Pertinente. Es decir, relevante y útil en el tiempo para facilitar las decisiones que serán tomadas sobre la base de esa información.
✔ Precisa. Es decir, adecuada para lo que se quiere medir y que refleje fielmente la magnitud del fenómeno estudiado.
✔ Oportuna. Es decir, disponible en el período de tiempo en el que la información es relevante.
✔ Económica. Es decir, que los costos en los que se incurre para obtener la información sean proporcionales a los beneficios y la relevancia que aporta.
Mira este video para profundizar los conceptos aprendidos en esta unidad. Aquí, el tutor experto en estadística y políticas públicas los explica con claridad y haciendo uso de recursos gráficos:
Un indicador es una expresión cualitativa o cuantitativa observable, que describe características, comportamientos o fenómenos de la realidad a través de la evolución de una variable o del establecimiento de una relación entre variables.
Al comparar la evolución de una variable o de una relación de variables con períodos anteriores, o con una meta o compromiso, se puede evaluar su desempeño y analizar su evolución en el tiempo.
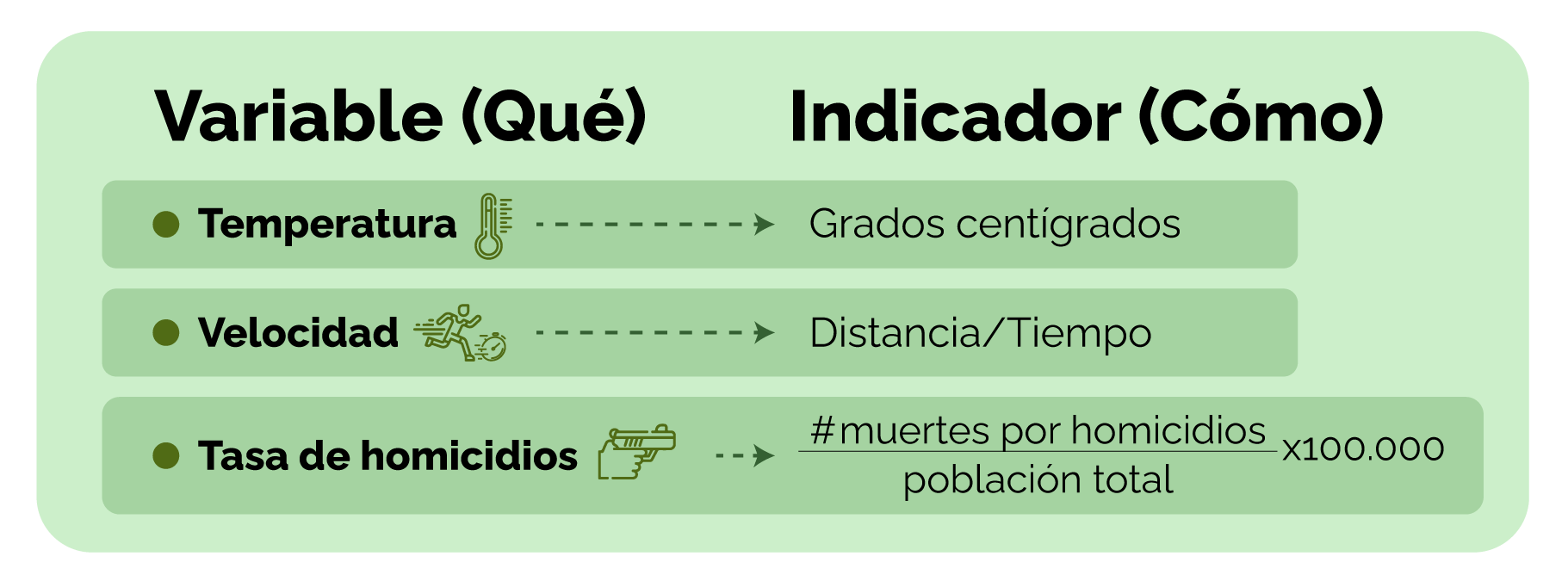
Los indicadores se construyen a partir de datos y deben cumplir con las siguientes características:
✔ Simplifican la realidad. Esto quiere decir que reflejan una dimensión de la realidad (económica, social, cultural, política, etc.) pero nunca intentar abarcarlas a todas.
✔ Permiten comparaciones. Esto quiere decir que facilitan revisar una situación actual frente a patrones establecidos en el pasado o a metas proyectadas a futuro.
✔ Comunican. Esto quiere decir que transmiten información relevante acerca de un tema y son útiles y aportan al proceso de toma de decisiones
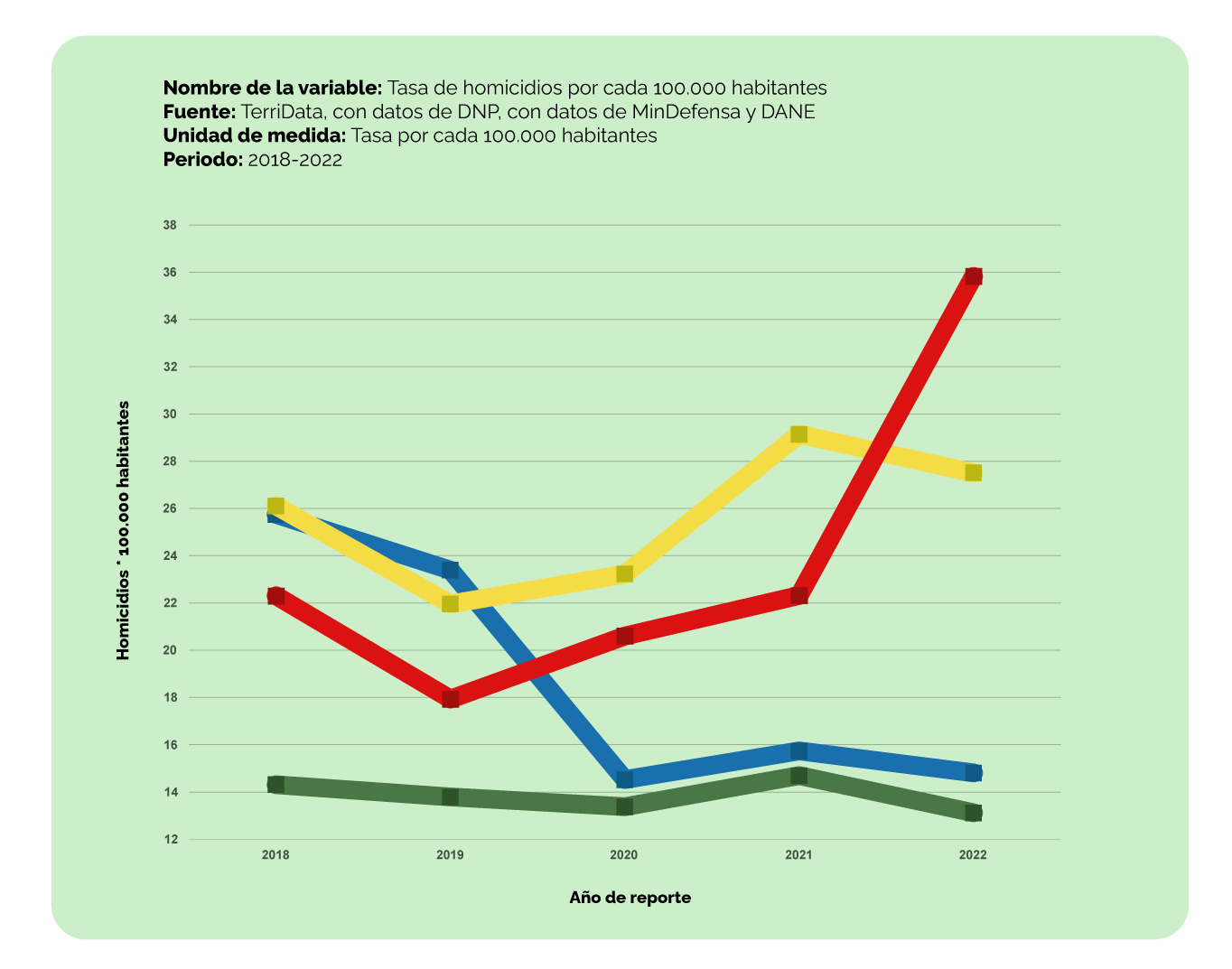
Observemos el indicador del gráfico: la tasa de homicidios. Fíjate cómo este indicador cumple con las características requeridas para todo indicador:
✔ Simplifica la realidad porque, aunque informa sobre un aspecto importante de la seguridad ciudadana, a partir de este indicador no se puede determinar qué ha llevado a esta situación.
✔ Permite comparaciones tanto en el tiempo como en relación con otras entidades territoriales.
✔ Comunica porque aporta información valiosa sobre la evolución de los homicidios a lo largo del tiempo o en un período específico.
Ahora bien, con base en la información que brinda la evolución en el tiempo y la comparación con otros municipios, se pueden analizar las posibles causas que han llevado a estos comportamientos en la tasa de homicidios y evaluar alternativas que permitan mejorar la seguridad. También es posible hacer seguimiento para revisar si las medidas adoptadas están logrando los efectos deseados o si es necesario hacer ajustes o cambiar de estrategia.
Los indicadores son herramientas útiles que permiten generar información para:
✔ Mejorar el proceso de diseño, implementación o evaluación de un plan, programa, o proyecto.
✔ Monitorear el cumplimiento de metas y compromisos.
✔ Cuantificar los cambios en una situación.
✔ Tomar mejores decisiones, basadas en evidencia.
LA DIFERENCIA ENTRE DATOS E INFORMACIÓN
A la hora de trabajar con indicadores tenemos que tener en cuenta que siempre deben ser analizados en contexto. Por eso, antes de continuar con los tipos de indicadores que existen, nos detendremos un momento para entender a fondo la diferencia entre datos e información. Para eso, continuaremos trabajando con el ejemplo del indicador tasa de homicidios.
Supongamos que hablando sobre seguridad ciudadana alguien dice que la seguridad en el municipio está terrible y que oyó que la tasa de homicidios había llegado a 20 personas por cada 100 mil habitantes… Pero esto, ¿qué significa realmente?
¿Qué opinarías tú acerca de una tasa de homicidios de 20 personas por cada 100 mil habitantes?
a) ¿Es baja?
b) ¿Es alta?
c) No sé
d) Necesito más información
Para poder establecer si esta tasa de homicidios es alta o baja, es necesario tener más información, porque si bien tenemos claro que entre más cercana a 0 es mejor, hay que saber si venimos de una situación donde la tasa de homicidio era más alta o más baja, con el fin de establecer si se estaba en una mejor situación, o no. Sólo cuando tengamos esa información podremos afirmar que la seguridad ciudadana se ha deteriorado o no.
Por ejemplo, si para 2023 el municipio representado con la línea verde registrara una tasa de homicidios de 20 personas por cada 100 mil habitantes, eso significaría un incremento importante que afecta de manera negativa su seguridad ciudadana (pues la tasa es muy alta frente a los periodos anteriores); mientras que la misma tasa de homicidios para el municipio representado con la línea roja implicaría una gran recuperación en este indicador y, por lo tanto, una mejoría en su seguridad ciudadana. Esto nos muestra que el mismo indicador (20 homicidios por cada 100 mil personas) tiene diferentes implicaciones para cada uno de los 4 municipios representados en la gráfica.
Con este ejemplo se busca ilustrar la importancia del contexto en el análisis de la información para darle sentido a lo que revelan los datos. Con esto, estamos aprendiendo la diferencia que existe entre datos e información.
Los datos son simplemente unidades de medidas (percepciones, números, observaciones, hechos y cifras) que, al estar desligadas de un contexto particular, carecen de sentido informativo.
La información es un conjunto organizado de datos procesados, que constituye un mensaje sobre un determinado fenómeno y proporciona significado o sentido a una situación en particular.
El dato “20 homicidios por 100.000 personas” no es por sí mismo información. Sólo se convierte en información cuando, al ser juntado con otros datos del contexto, proporciona un entendimiento significativo y relevante sobre una situación en particular.
Los datos sólo se convierten en información cuando aportan significado, relevancia y entendimiento, en un tiempo y lugar específico.
TIPOS DE INDICADORES
Existen cuatro tipos de clasificaciones comunes de indicadores:
- Según tipo de medición (cualitativa o cuantitativa).
- Por nivel de intervención (Según etapa de la cadena de valor).
- Según jerarquía.
- De calidad (de acuerdo con el concepto que se quiere medir).
En esta unidad aprenderás en qué consisten estas 4 clasificaciones.
INDICADORES POR NIVEL DE INTERVENCIÓN
Estos indicadores miden la relación entre recursos o insumos, resultados e impactos, de tal manera que se pueda establecer si hemos cumplido la metas que nos habíamos trazado con los recursos que teníamos disponibles.
Según esta clasificación, hay 5 tipos de indicadores que se establecen de acuerdo con cada una de las fases de un proceso llamado “la cadena de valor”.
En esta ilustración encuentras un ejemplo de estos 5 tipos de indicadores según la cadena de valor:
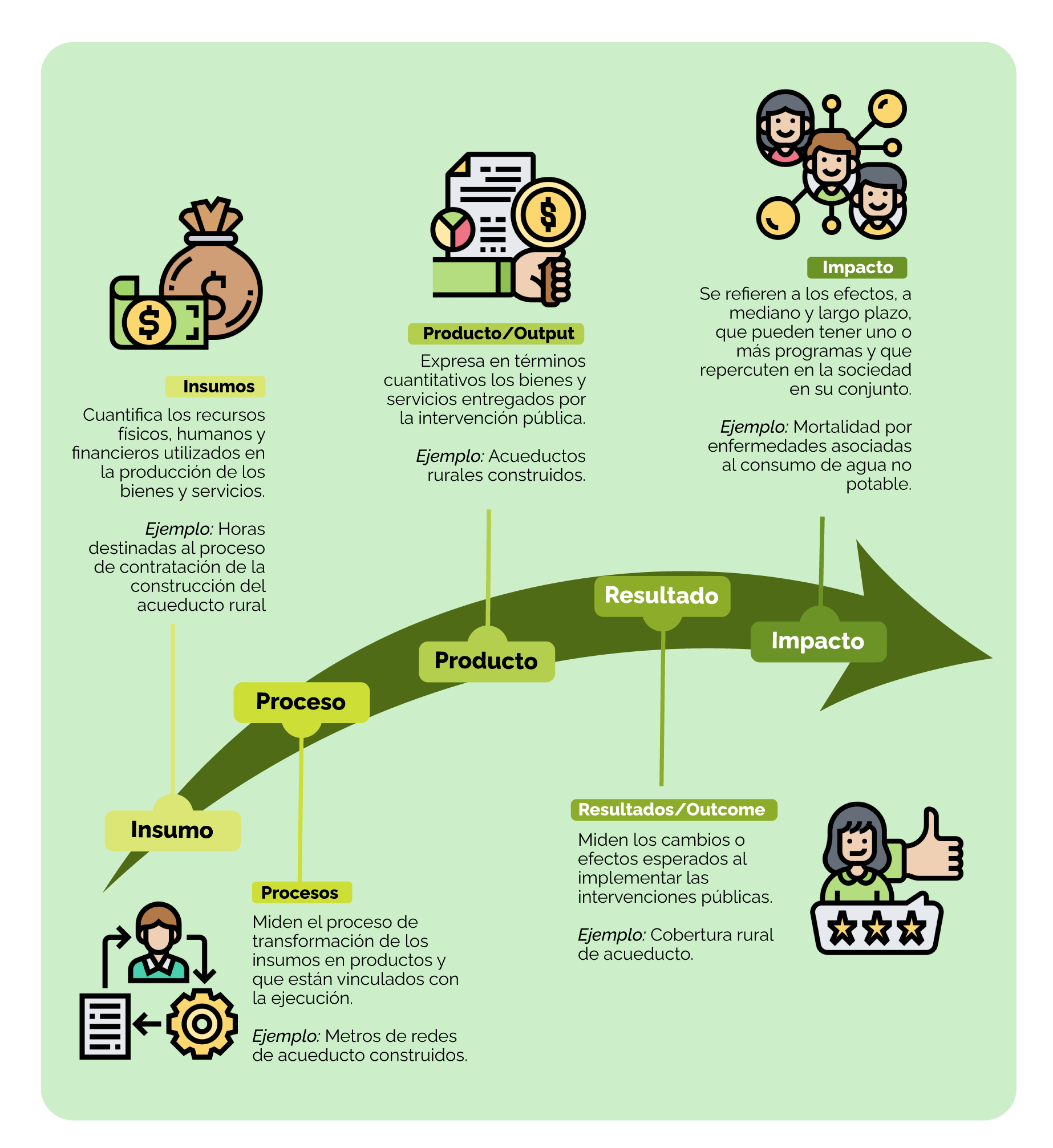
Esta clasificación de indicadores es importante porque en Colombia, a partir del enfoque de gestión pública orientada a resultados, que es un modelo de gestión que pone énfasis en los resultados y no solo en los procedimientos, se introdujo el uso de la cadena de valor público como estructura fundamental para la representación de las intervenciones públicas. Con esta estructura el Departamento Nacional de Planeación -DNP- evalúa el desempeño de las intervenciones públicas.
La estructuración de proyectos a través de la Metodología General Ajustada (MGA), que es el modelo con el cual se deben formular los proyectos de inversión pública en Colombia, incorpora el uso de la cadena de valor y construyó un catálogo de productos.
Este catálogo, construido por el DNP, fue hecho con el fin de estandarizar los “bienes o servicios que hacen parte del portafolio que como Estado se entregan hacia la población objetivo, y cada uno de ellos está acompañado de indicadores estandarizados bajo criterios técnicos y metodológicos para la medición de su entrega”.
El catálogo está disponible en la página web de mesa de ayuda de la MGA y se puede consultar aquí: https://mgaayuda.dnp.gov.co/.
INDICADORES SEGÚN JERARQUÍA
Esta clasificación de indicadores depende del nivel organizacional en el que se miden. Según este criterio, se establecen dos tipos de indicadores: indicadores de gestión e indicadores estratégicos.
Indicadores de gestión
Su función principal es medir la relación entre los recursos / insumos y los procesos. En este grupo se incluyen los indicadores administrativos y operativos.
Indicadores estratégicos
Permiten hacer una evaluación de productos, efectos e impactos. Incluyen todos los indicadores que hacen parte del sistema de seguimiento y evaluación de una organización.
Interrelación entre indicadores, según nivel de resultados y jerarquía
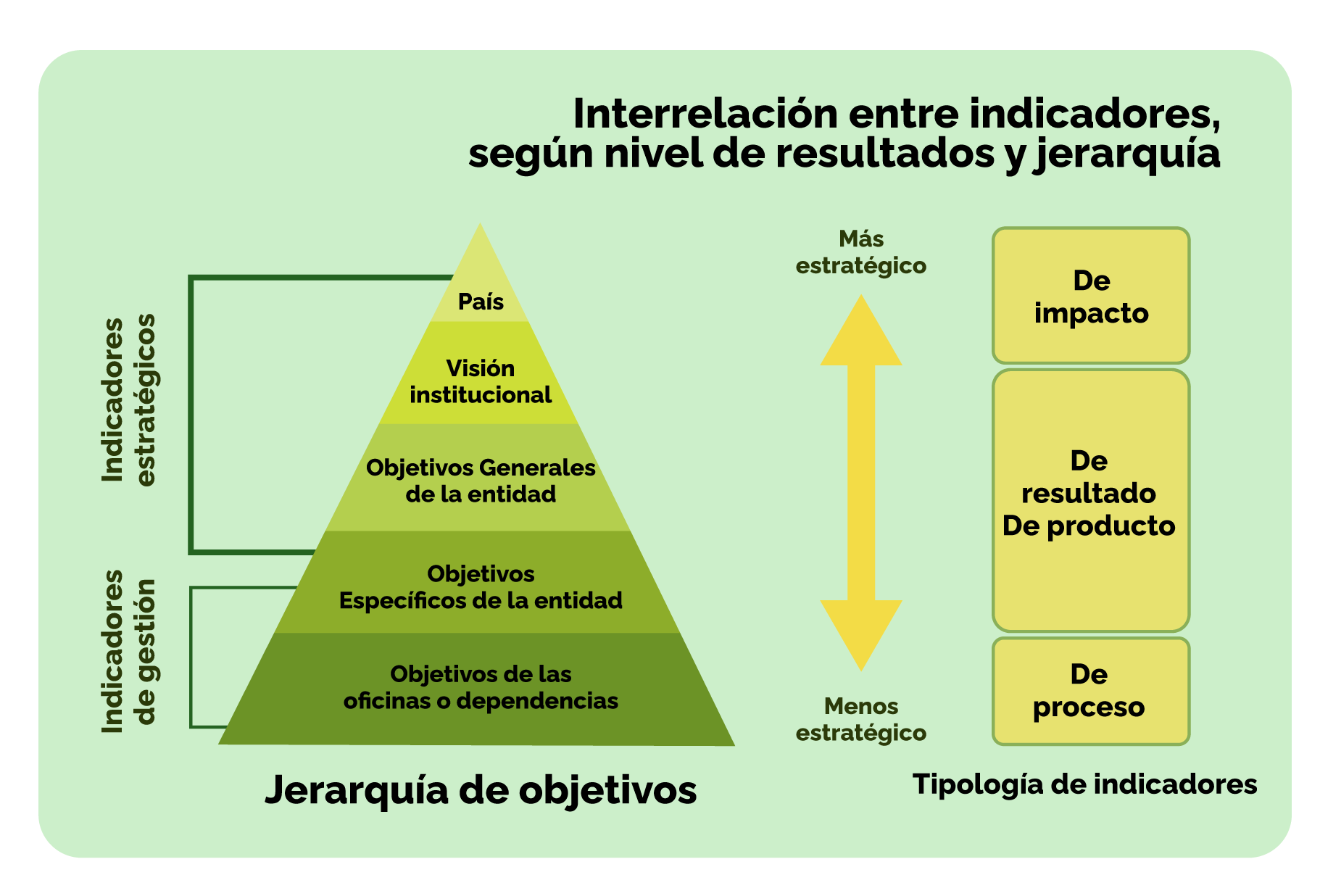
Fuente: DANE. https://www.dane.gov.co/files/planificacion/fortalecimiento/cuadernillo/Guia_construccion_interpretacion_indicadores.pdf
INDICADORES DE CALIDAD
Esta clasificación de indicadores se establece a partir de tres conceptos que tienen en cuenta distintas variables. Esos conceptos son: eficacia, eficiencia y efectividad.
Indicadores de eficacia
Expresan el logro de los objetivos, metas y resultados de un plan, programa, proyecto o política. Se obtienen al comparar una meta alcanzada en relación con la meta planeada.
Eficacia=(Meta alcanzada)/(Meta planeada)×100
Indicadores de eficiencia
Permiten establecer la relación de productividad en el uso de los recursos.
Eficiencia=(Logro alcanzado)/(Recursos disponibles)×100
Indicadores de efectividad
Este tipo de indicadores tienen en cuenta tanto la eficiencia como la eficacia para medir si se están utilizando adecuadamente los recursos en el cumplimiento de resultados.
Su objetivo es medir el impacto de una intervención.
¿POR QUÉ ES ÚTIL SABER QUE HAY DISTINTOS TIPOS DE INDICADORES?
De acuerdo con lo que se quiera medir y evaluar, se pueden usar estos tipos de indicadores que ayudan a tomar decisiones informadas y a modificar o cambiar el programa o proyecto que se esté implementando para producir mejores resultados.
Puedes ver el siguiente video para complementar, con explicaciones detalladas por parte del tutor, algunos de los contenidos aprendidos sobre indicadores.
Ya hemos visto cómo los indicadores permiten visibilizar una situación y con esto tomar mejores decisiones. Pero, ¿te has preguntado si los datos pueden “esconder” información?
En esta unidad aprenderás conceptos que te ayudarán a evitar a usar los datos de formas que invisibilizan información relevante.
LOS DATOS AGREGADOS
Vamos a ver un ejemplo. Supón que es la hora del almuerzo y entre 8 compañeros piden una pizza para compartir. Cuando llega la pizza, resulta que esta viene partida de la siguiente manera:

Mientras se esperaba que la pizza se repartiera de forma equitativa entre todos los comensales (1/8 para cada uno), la realidad es que a unos les tocó más que a otros.

Esto es lo que ocurre con los datos agregados. Los datos agregados asumen que los fenómenos se distribuyen equitativamente entre todos los individuos o grupos analizados. Sin embargo, la realidad es que la repartición no siempre es equitativa y en muchos casos las desigualdades se dan en relación a las características de los individuos o grupos.
Además, entre más desigual sea una repartición, los datos agregados menos reflejan la realidad, especialmente la situación de los extremos.
Fíjate detenidamente en estas dos reparticiones:
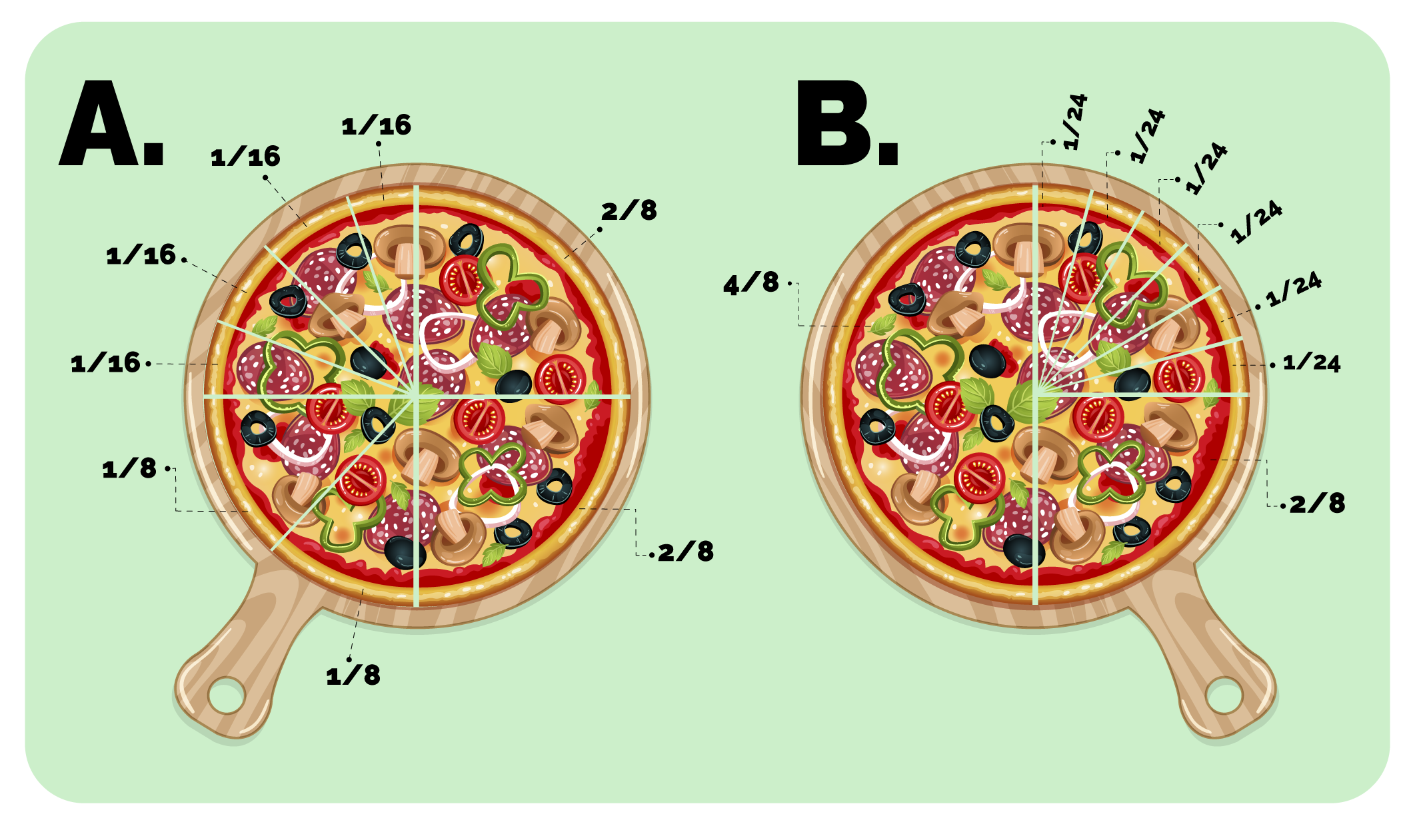

Para el caso de la pizza, el dato promedio es el que nos diría cuánto le tocaría a cada comensal si la pizza se repartiera en partes iguales. En la pizza A y en la pizza B el dato promedio es el mismo: 12,5. ¡Pero eso no quiere decir que las reparticiones hayan sido iguales!
Al observar las dos reparticiones, se puede establecer que hay una mayor distancia entre el dato promedio y los valores “reales/observados” de la pizza b, que entre el dato promedio y los valores “reales/observados” de la pizza a.
Por lo tanto, los datos agregados invisibilizan las desigualdades que hay entre diferentes grupos, individuos o elementos.
Esta repartición desigual ocurre en muchos fenómenos de la vida real, por ejemplo, con la riqueza.
De acuerdo con los cálculos de la Oxfam, el 90% más pobre del mundo solo se quedó con el 10% de la riqueza generada entre 2020 y 2021, mientras que el 1% más rico obtuvo el 63% de la riqueza creada en ese mismo periodo de tiempo.

Y en Colombia, de acuerdo con los datos del World Inequality Database, en 2021 el 1% más rico tenía el 33% de la riqueza, mientras que el 50% más pobre tenía solo el 3,9% de la riqueza (https://wid.world/es/country/es-colombia/).
Es decir, si la población colombiana fueran 50 personas, así sería la repartición de la riqueza:
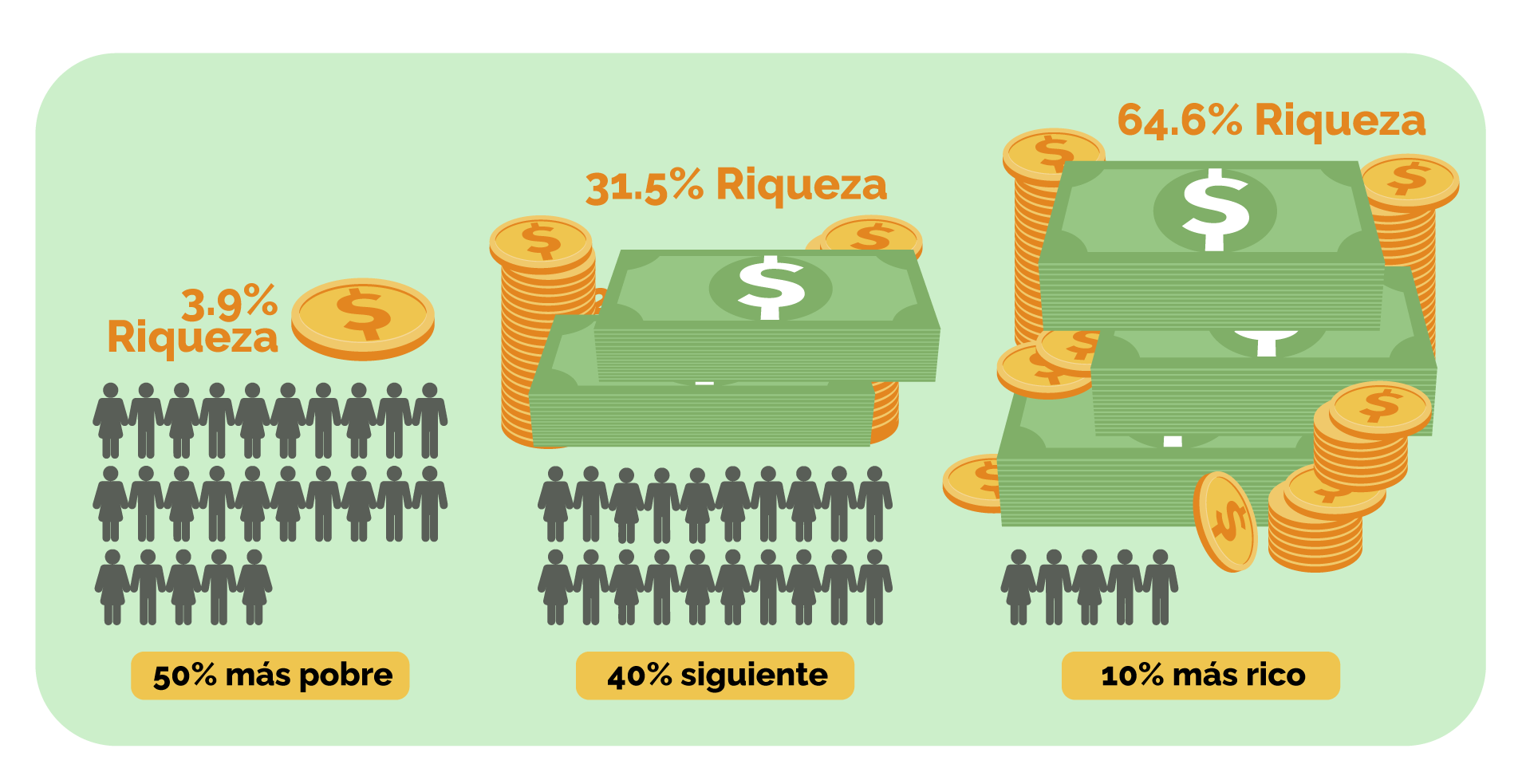
Y así se vería la “pizza de la riqueza”:
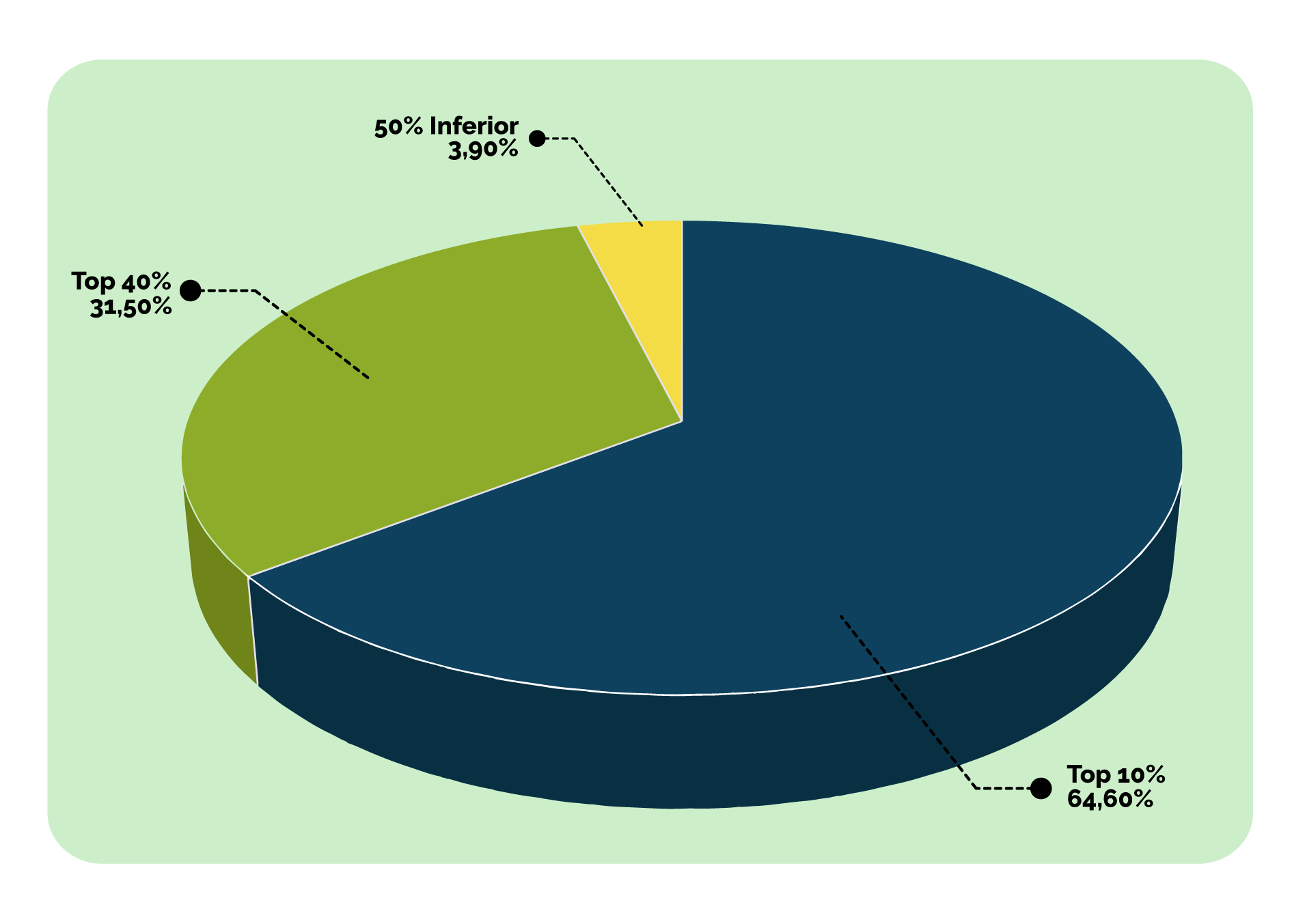
Si comparamos estos datos con indicadores agregados como el PIB per cápita (el indicador utilizado para establecer el crecimiento económico medio por habitante de Colombia), se puede ver cómo estos esconden la desigualdad que existe entre las personas, puesto que al dividir el total del PIB entre su número de habitantes, se asume el mismo nivel de renta para todos, ignorando las diferencias económicas entre los habitantes.
Esto nos demuestra, nuevamente, que los datos agregados “esconden” diferencias al interior de los elementos analizados, ya sea entre categorías, entidades territoriales o grupos de personas.
Veamos algunos ejemplos más.

LO QUE DESCUBRIMOS AL DESAGREGAR DATOS
¿Qué podemos descubrir cuando desagregamos estos datos? Ahora que has aprendido que los datos agregados esconden información, vas a aprender lo que se revela al desagregarlos.
DESAGREGAR POR NIVEL EDUCATIVO
Veamos qué pasa si se observan las coberturas de manera desagregada por nivel educativo.

¿Qué observas al comparar la gráfica de cobertura en educación total, educación primaria y educación media?
Fíjate que al analizar la cobertura bruta por nivel educativo se puede ver que mientras la cobertura en educación primaria ha caído a lo largo del tiempo y siempre ha tenido valores superiores a los de la educación total, la cobertura en educación media tiene un comportamiento creciente pero inferior a los de la cobertura total.
Por tanto, al agregar los datos en la cobertura de educación total, se invisibilizan estas diferencias por niveles educativos, y esto limita y puede sesgar la toma de decisiones. En cambio, al desagregar los datos por nivel educativo descubrimos diferencias que nos llevan a entender mejor una situación y considerar mejores soluciones.
DESAGREGAR POR NIVELES TERRITORIALES
Ahora veamos qué pasa si analizamos las mismas coberturas desagregadas por nivel territorial.
En este caso, ¿qué diferencias estaríamos omitiendo si trabajamos con los datos agregados?
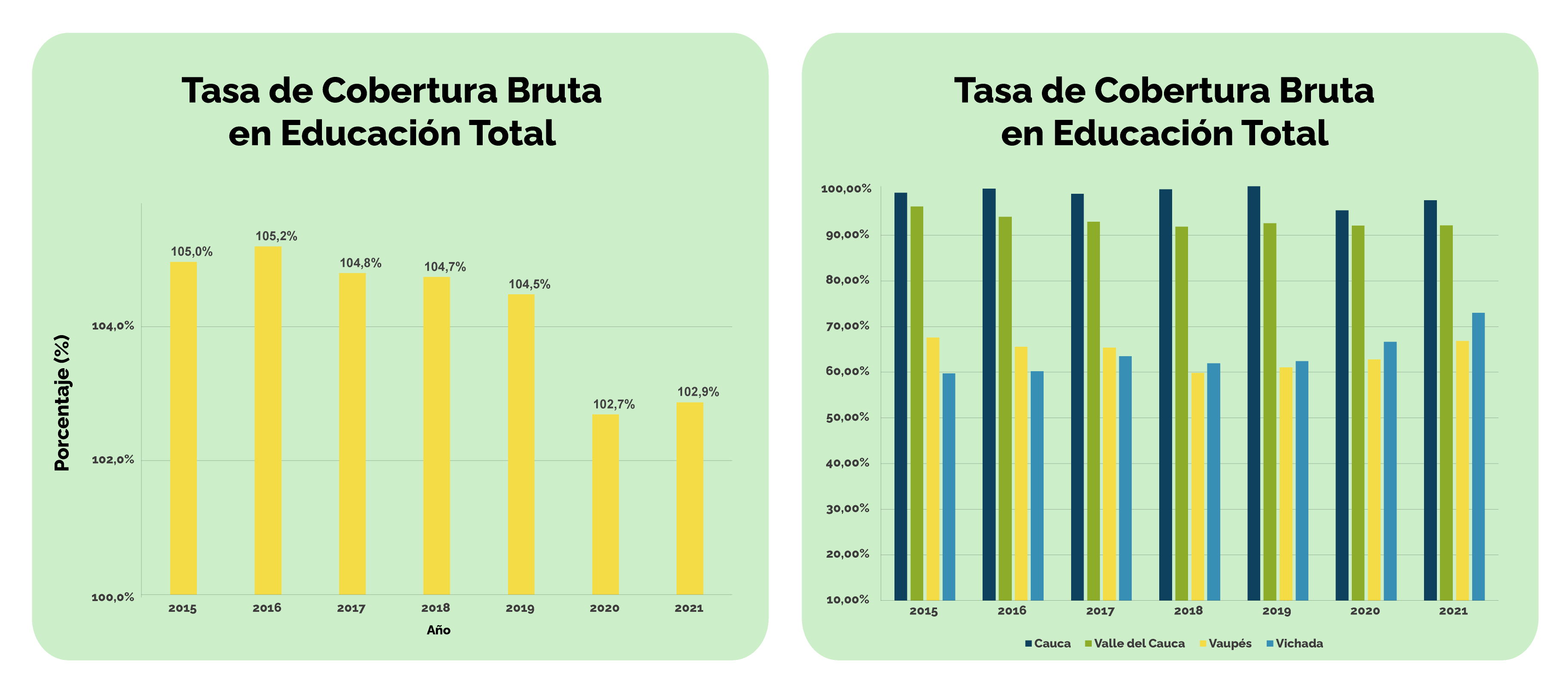
Al comparar los datos agregados a nivel nacional con datos desagregados para diferentes entidades territoriales se puede ver cómo los datos nacionales “esconden” diferencias importantes a nivel departamental, pues los datos agregados no permiten ver que hay departamentos que tienen coberturas que son aproximadamente sólo el 65% de lo que refleja el promedio nacional.
Al no ver estas diferencias se pierde la posibilidad de priorizar o crear estrategias diferenciales que permitan atender a quienes más lo requieren.
Y si se desagregan aún más los datos, por departamento y nivel educativo, se pueden ver y analizar otros fenómenos.

Con esta gráfica se puede ver cómo Vichada ha ido incrementando su cobertura en educación primaria, incluso superando los niveles de entidades territoriales como Bogotá y Cauca en 2021, mientras que su cobertura en educación media permanece casi constante y en valores bajos comparados con los otros departamentos. Por su parte, el Valle del Cauca ha tenido un comportamiento opuesto al de Vichada, puesto que ha disminuido su cobertura en educación primaria, mientras que ha aumentado la de educación media, aunque la magnitud de los cambios ha sido menor.
Poder identificar estas diferencias permite formular preguntas que ayuden a entender la situación de cada una de las entidades territoriales. Identificar estas diferencias también facilita el diseño de estrategias diferenciadas que atiendan las necesidades de cada uno de los departamentos.
DESAGREGAR POR GRUPOS POBLACIONALES
Ahora veamos qué pasa si analizamos las mismas coberturas educativas desagregadas por grupos poblacionales.
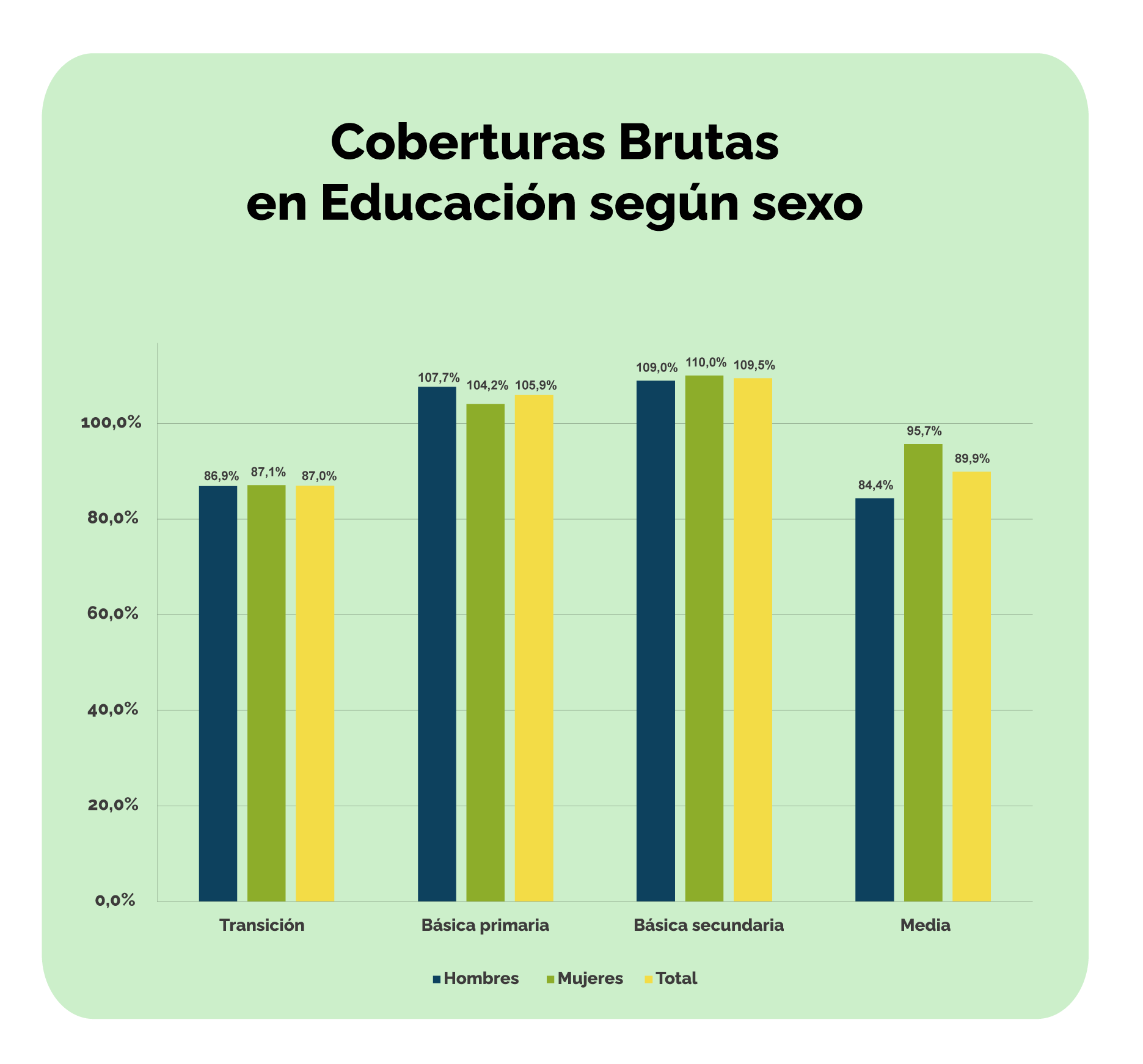
Los datos agregados invisibilizan diferencias entre los distintos grupos poblacionales: por edad (ciclo de vida), por pertenencia étnica, por género o por discapacidad.
Siguiendo con el ejemplo de cobertura bruta en educación, al analizar los datos desagregados por sexo y nivel educativo, a nivel nacional se puede observar que hombres y mujeres tienen tasas de cobertura similares en los niveles de transición, primaria y secundaria, pero en educación media la diferencia es de 11.3 puntos porcentuales, a favor de las mujeres.
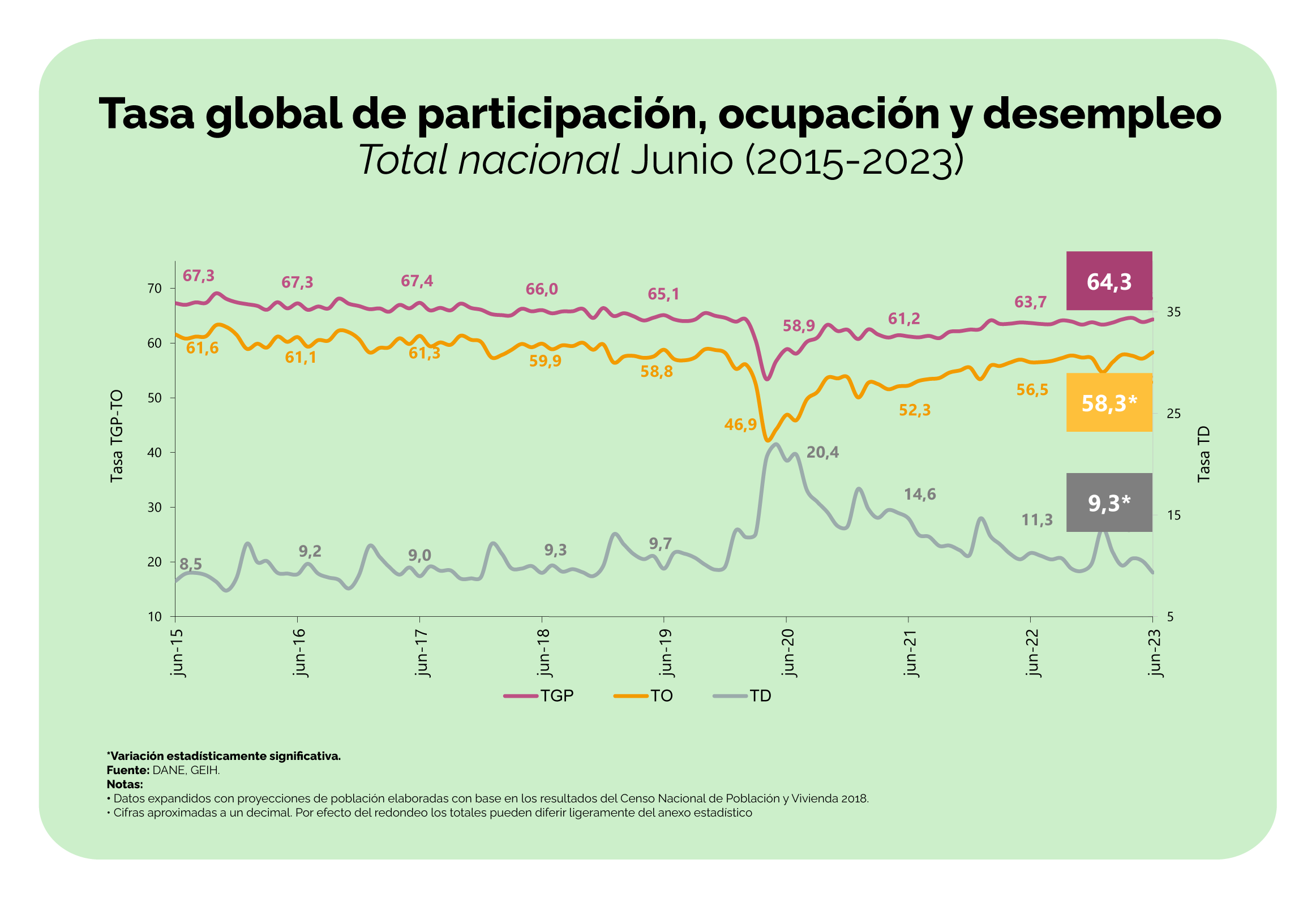
Ahora bien, si se analiza el comportamiento del mercado laboral por sexo se pueden observar unas diferencias más amplias entre hombres y mujeres.

Fuente: https://www.dane.gov.co/files/operaciones/GEIH/pres-GEIH-jun2023.pdf
Al analizar estas dos gráficas… ¿Qué podríamos decir frente a lo que presentan los datos agregados para el total de la población y los datos desagregados por sexo?
Al observar la primera gráfica se podría decir que todos los indicadores, tasa global de participación (TGP), tasa de ocupación (TO) y tasa de desempleo (TD), se han venido recuperando desde el 2020 y, que esta última volvió a tener una cifra de un dígito (más baja del 10%).
Complementando esta información con la segunda gráfica, se puede advertir que, si bien la tasa de desempleo volvió a tener un dígito considerando los datos agregados, las mujeres siguen teniendo una tasa de desempleo de dos dígitos (11,6%), a pesar de que ha venido disminuyendo desde 2020. El otro factor para destacar es que la brecha de la tasa de desempleo entre hombre y mujeres es la más baja que se registra desde el 2014, ubicándose en 3.9 puntos porcentuales (p.p.).
La brecha de género es una medida que muestra la distancia entre mujeres y hombres respecto a un mismo indicador.
https://www.dane.gov.co/files/operaciones/GEIH/pres-GEIH-jun2023.pdf
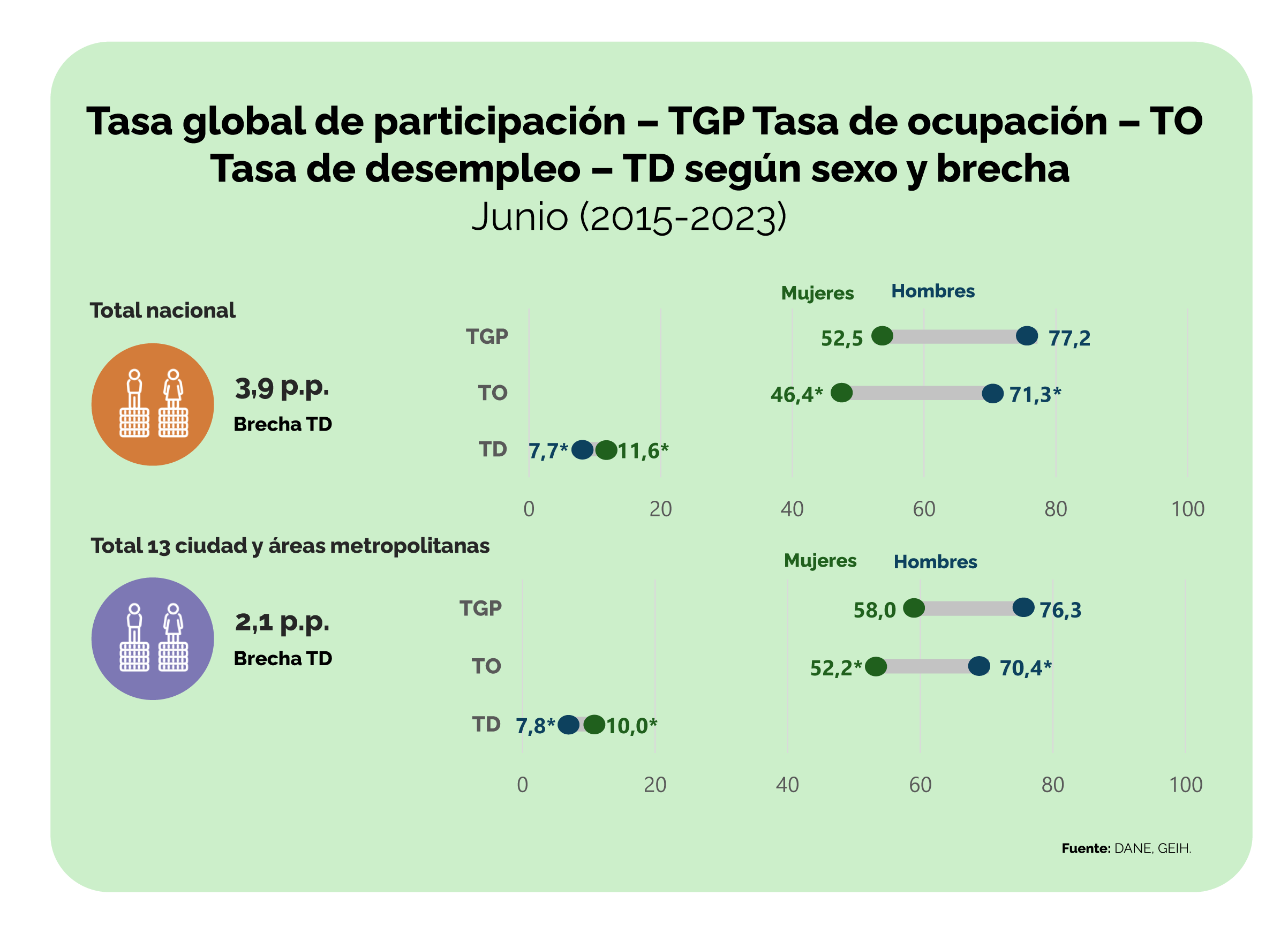
Fuente: https://www.dane.gov.co/files/operaciones/GEIH/pres-GEIH-jun2023.pdf
Por lo tanto, al analizar los principales indicadores del mercado laboral desagregados por sexo a nivel nacional, se puede establecer que la brecha entre hombres y mujeres era de 24,7 p.p. en la tasa global de participación (TGP), 24.9 p.p. en la tasa de ocupación, y 3,9 p.p. en la tasa de desempleo, todas a favor de los hombres. Lo mismo se observa para las 13 principales ciudades y áreas metropolitanas, aunque en este caso las brechas de género son más pequeñas.
Esto significa que las mujeres experimentan mayores dificultades que los hombres en el mercado laboral, pues no solo participan menos, sino que tienen tasas de desempleo más altas y de ocupación más bajas.
Visibilizar estas diferencias solo es posible si se presentan datos desagregados. A partir de esta información los gobiernos pueden, por ejemplo, tomar decisiones para abordar de manera diferenciada las necesidades de mujeres y hombres, y así, cerrar la brecha de género.
https://www.dane.gov.co/files/operaciones/GEIH/pres-GEIH-jun2023.pdf
CÓMO ACCEDER A DATOS DESAGREGADOS
Si bien en el país hace falta que haya una mayor disponibilidad de datos que permitan estos niveles de desagregación a nivel territorial y poblacional en muchas dimensiones, el DANE ha incorporado 5 enfoques diferenciales en los procesos de producción de información estadística. Es de esperar que esto se refleje en una voluntad por avanzar en la producción de datos desagregados que permitan visibilizar las situaciones de estos grupos poblacionales.
Mientras eso sucede, para poder consultar algunos indicadores de resultado desagregados, se ha construido una guía que tiene un paso a paso para consultar indicadores de algunas páginas web que tienen datos oficiales desagregados por sexo.
Descarga aquí la guía.

También se ha construido un visor donde podrás consultar los indicadores por sexo a nivel territorial.
Descarga aquí el visor.


De acuerdo con la guía para la inclusión del enfoque diferencial e interseccional del DANE, el enfoque diferencial se define como una perspectiva para obtener y difundir información sobre grupos poblacionales con características particulares como edad, género, pertenencia étnica, campesina y discapacidad, entre otras. Su objetivo es visibilizar situaciones de vida particulares y desigualdades, para guiar la toma de decisiones públicas y privadas.
(Fuente: https://www.dane.gov.co/files/investigaciones/genero/guia-inclusion-enfoque-difencias-intersecciones-produccion-estadistica-SEN.pdf).
DATOS DESAGREGADOS Y ANÁLISIS INTERSECCIONAL
Cuando se analizan conjuntamente dos o más de estas características, por ejemplo, mujeres indígenas u hombres campesinos mayores de 60 años, se habla de interseccionalidad. Por lo tanto, al hablar de enfoque interseccional nos referimos a una perspectiva que permite conocer la presencia simultánea de dos o más características diferenciales de las personas (género, discapacidad, etapa del ciclo vital, pertenencia étnica y campesina, entre otras) que en un contexto histórico, social y cultural determinado incrementan la carga de desigualdad, produciendo experiencias sustantivamente diferentes entre los sujetos.
Continuando con el análisis del mercado laboral por sexo, de acuerdo con el siguiente cuadro, ¿qué podría decirse frente a la ocupación de las mujeres según dominio geográfico?

De las gráficas anteriores se ha podido establecer que las mujeres tienen una menor ocupación que los hombres, dato que se evidencia en este cuadro con el número de personas ocupadas por sexo.
Al analizar la distribución de los ocupados por dominio geográfico se puede ver que la mayoría de las mujeres se ocupan en las 13 principales ciudades y áreas metropolitanas del país (al igual que los hombres, pero las mujeres en mayor proporción), y en este dominio también se ha presentado el mayor crecimiento de la ocupación femenina.
Mientras que en las zonas rurales (centros poblados y rural disperso), las mujeres se ocupan proporcionalmente menos que los hombres (14,9% versus 24,8%), aun cuando el crecimiento de la ocupación femenina en este dominio es muy superior a la masculina.
De acuerdo con esta información cabe preguntarse, ¿por qué la ocupación femenina es tan baja en las zonas rurales?

La disponibilidad de datos desagregados por sexo y dominios geográficos permiten este análisis intersectorial. Sin esta información sería imposible visibilizar estas situaciones y cuestionarse frente a las razones que llevan a estos resultados con el fin de diseñar políticas y medidas que lleven a una mayor equidad entre grupos poblacionales.
¡VERIFICA LO APRENDIDO!
EVALUACIÓN FINAL
Te invitamos a responder este test de evaluación sólo si has trabajado el contenido completo de todas las unidades del módulo 1.
El test está compuesto de 7 preguntas de selección múltiple con una única respuesta correcta.
Al completar el test obtendrás los resultados. Analiza tu desempeño y repasa los temas en los que no hayas seleccionado la respuesta correcta.
Después de leer el enunciado cuidadosamente, selecciona la respuesta correcta. Sólo una respuesta es correcta.
